Introduction
This article describes the process of loading & stress testing on the EHRServer to evaluate performance, resource consumption, and to detect potential issues.
The goal was to check if the EHRServer could keep acceptable performance/response times, and that resource usage levels (CPU & memory) where stable while the system is under stress, hopefully without dying.
This is not a rigorous benchmark, we might do that in the future.

Context
Since I started designing the EHRServer about five years ago, the focus was on getting an openEHR compliant clinical data repository working, then open source it to the community. The key challenges I had were: how to store openEHR data and how to query openEHR data. That sounds simple, but to get a generic solution that can store and query any kind of data structure, and be compliant with the openEHR standard, was a huge design and implementation challenge. It is good to remember at that time there wasn't any open source openEHR clinical data repository available and there wasn't any official guide on how to create one. I needed to start from scratch, doing a lot of research, testing different designs and technologies, etc. When I finally got things working in an usable way, my focus migrated to other areas like usability, security, robustness and performance.
I always try to design and implement systems as robust as possible. I like to have many test cases and consider different usage scenarios. In addition, I do functional testing, were I manually test every single functionality many times. The only missing test until now was a load / stress test. So in the last couple of months I created an application called loadEHR that serves as a transaction intensive client for the EHRServer.
With loadEHR we have the ability to create EHRs and commit clinical documents to the EHRServer, with the option of establishing the number of EHRs and clinical documents to be created. I wanted to execute lots of transactions, even have many loadEHR instances running in parallel against the same instance of the EHRServer. I didn't just want to do load / stress testing on the EHRServer, I really tried to kill it.
If you can't measure it, you can't manage it
How can we know the how much resources an application requires if we don't try to reach its limits?
Many software companies and individual developers don't do that, and the result is broken applications when usage peaks occur. My opinion is if you want to have 10 users, you need to test your system with a usage simulation of 100 users. I don't like surprises, and neither my users, so what to do?
Load test is a very standard technique for testing how much "abuse" a system can handle, and measure the resources consumed while doing the test. This is great to simulate worst case scenarios, and to detect resource consumption peaks for certain load levels, so it is crucial to estimate resources needed for a production environment. With this, we can detect if the underlying infrastructure (CPU, memory, disk, network) doesn't have enough power, of if we have problems in our systems, like memory leaks causing memory usage to grow until an "out of memory" exception is thrown, or causing the system to perform poorly (increasing response times).
Load tests on the EHRServer
On some scenarios we might have one transaction per hour, on other scenario thousands of transactions per minute. For any scenario, we need to know the power that EHRServer needs underneath (CPU, memory, disk I/O, network bandwidth) to support that kind of load.
Most EHRServer users have low transaction level scenarios, but lately the EHRServer got a lot of attention and I wanted to be sure that one instance can support a huge load, preparing to scale in the near future. But to scale, we need to have a correlation between the usage level and the CPU, memory, disk and network needed to support that usage level with acceptable performance levels.
Methodology
I tested two EHRServer instances, one on a small not dedicated virtual machine on my computer, and the other on a 1CPU/2GB RAM server on the cloud on a dedicated server I deployed on Linode.
The loadEHR was configured to create EHRs then commit openEHR clinical documents (compositions) to those EHRs. In the virtual machine I created around 10K EHRs (each patient has one EHR) and committed about 9 documents to each EHR with realistics clinical information (diagnosis, medication, pregnancy history, etc). While the load phase was running, I was using VisualVM to check memory and CPU consumption.
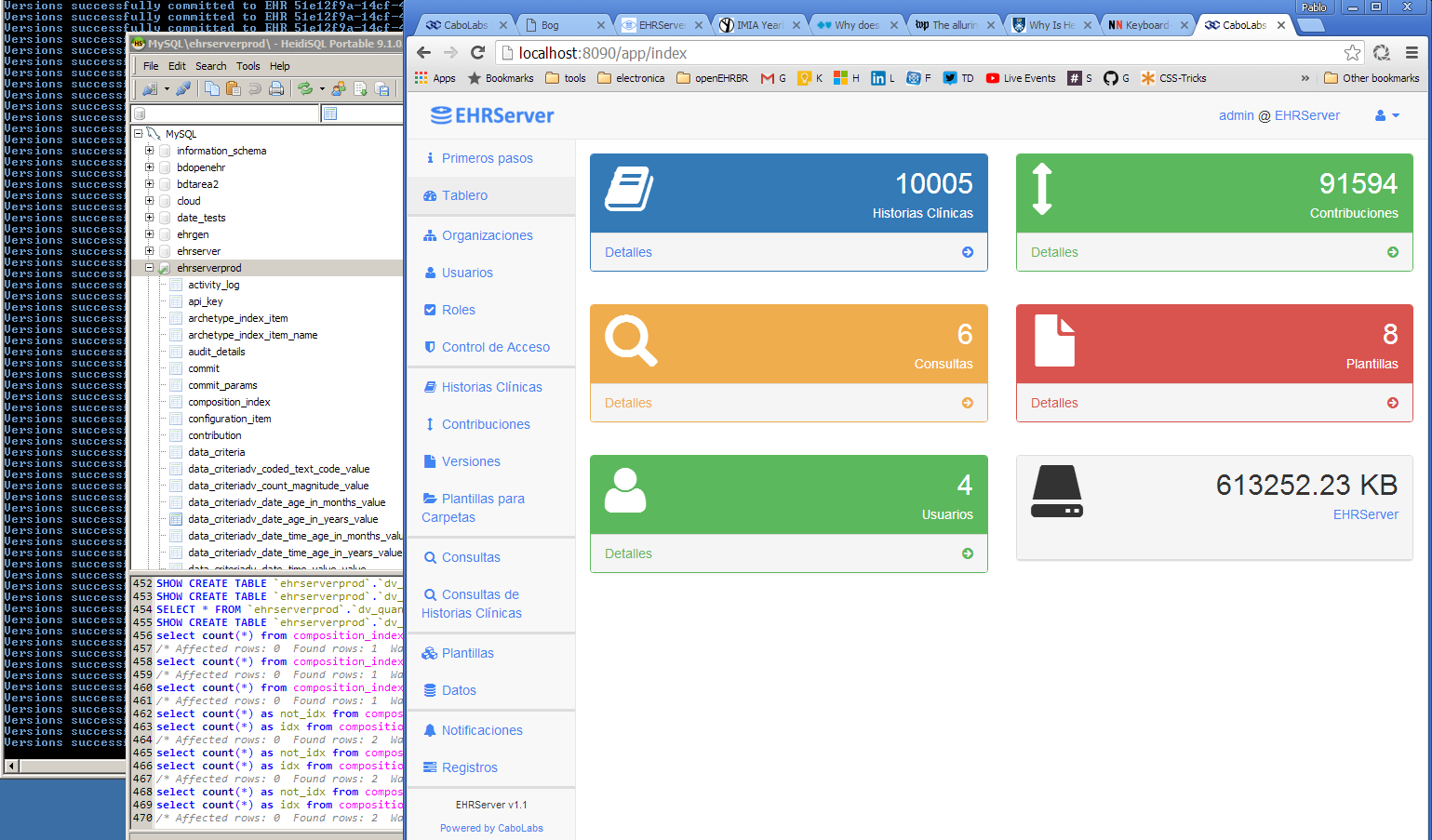
EHRServer Web Console after loading 10K EHRs and commiting around 9 documents per EHR.
The commit on the EHRServer has two phases. On the first phase, the EHRServer receives the clinical documents, it validates them against an XML Schema, and stores the full documents. The second phase, that runs in background, loads the documents, extract some data values, and stores that in a relational database (data indexing process). The indexed data is used to execute data queries.
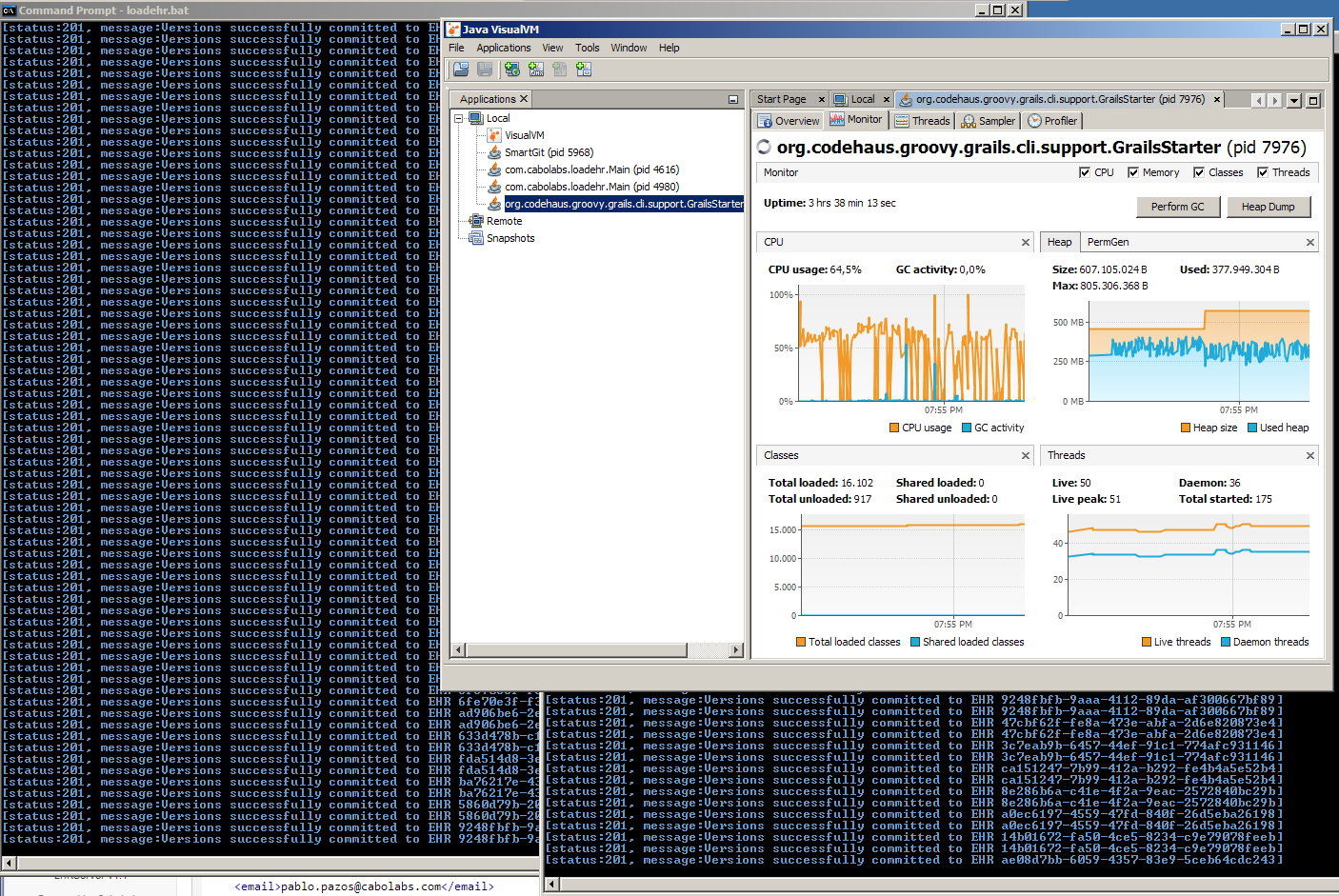
VisualVM showing memory and CPU usage while 2 instances of the loadEHR run in the background
To my surprise, memory and CPU usage was steady and the whole load work ended successfully without any issues on the EHRServer side. I didn't succeed on killing the EHRServer, it is still alive!

The whole load process took about a day on the local virtual machine and a couple of hours on the cloud server. Consider the load was 8x bigger on the local virtual machine and the cloud server to runs much faster. Of course the cloud server added some network latency since data travels through internet while in the local virtual machine both EHRServer and loadEHR where running on the same machine, so network latency is almost nothing.
On the second part of the test, I wanted to execute some queries over the data that was loaded by loadEHR. The goal was to check the response time of the queries while retrieving data from a big database. In the EHRServer there are two types of queries, data queries (return data points) and compositions queries (return clinical documents). I tested different queries and results came back in acceptable response times, most queries were executed under half a second. So far so good.
Conclusion
This kind of test was necessary to verify the EHRServer behaves as expected under heavy stress, and it should be repeated from time to time to check for possible negative impact on performance or resource consumption from the development of new features.
One conclusion is that the current cloud server can support heavy loading without any expansion of resources, but at some point in the future scaling will be needed. Good news is the EHRServer didn't show any memory leaks or CPU/memory peaks while testing, resource usage was steady or growing slowly.
One nice thing of this work is we ended up developing a test tool we and the community can use for future testing of the EHRServer. We will continue improving the loadEHR to make it an official test suite for the EHRServer. Please try it and let us know how can we improve it.